
Secure Boot und Firmware-Schutz in eingebetteten Systemen
Benutzer von eingebetteten Geräten – von Industriecontrollern bis hin zu Unterhaltungselektronik – sind sich oft nicht der versteckten Schwachstellen bewusst, […]


Optimierung ist ein entscheidender Teil des Softwareentwicklungsprozesses, der dabei hilft, viele geschäftliche Ziele zu erreichen. Allerdings erfordert sie Ressourcen, die möglicherweise an anderer Stelle eingesetzt werden könnten. Anwendungen auf Basis von Qt QML, wie jede andere Software, fallen unter dieses Prinzip. In diesem Beitrag möchte ich darauf eingehen, warum es sich lohnt, Ihre Software zu optimieren, und einige Techniken vorstellen, die Sie verwenden können, um die Leistung von Anwendungen mit Qt Quick zu verbessern.
Zu Beginn möchte ich klarstellen, dass ich bei der Erwähnung von Optimierung nicht nur die Optimierung auf Quellcode-Ebene meine, sondern auch die Optimierung auf Design-Ebene. Optimierung auf Quellcode-Ebene konzentriert sich auf Details wie die Frage, ob `while(1)` schneller ist als `for(;;)`. Die Grundidee der Optimierung auf Design-Ebene ist sicherzustellen, dass die verfügbaren Ressourcen bestmöglich genutzt werden, um die gesetzten Ziele innerhalb der vorhandenen Einschränkungen zu erreichen.

Bevor wir uns mit den Details der Optimierungstechniken befassen, sollten wir die grundlegende Frage klären: Warum optimieren? Für einige von Ihnen mag die Antwort offensichtlich sein, aber ich möchte dennoch darauf eingehen und hoffe, eine Diskussion anzuregen.
In einer perfekten Welt hätten wir eine effektive Architektur, die es uns ermöglicht, von Anfang an eine optimale und effiziente Implementierung zu erstellen, die während des gesamten Lebenszyklus der Software genutzt wird. Doch in der Realität gibt es keinen Menschen, der alle Eventualitäten eines Projekts vorhersehen kann. Unerwartete Erweiterungen des Projektumfangs durch ressourcenintensive Funktionen, die Einführung neuer Standards und Technologien, die eine effizientere Umsetzung derselben Logik ermöglichen, oder einfach menschliche Fehler, die zur Erstellung suboptimaler Lösungen führen, sind nur einige Beispiele. Es gibt viele Szenarien, die dazu führen können, dass Lösungen entstehen, die zwar funktional, aber nicht effizient genug sind.
Warum sollten wir zusätzliche Ressourcen und Zeit investieren, um bestehende Funktionen zu überarbeiten, die bereits in die Codebasis integriert sind? Ist es das wert? Um Ihnen bei der Beantwortung dieser Frage zu helfen, habe ich vier allgemeine Gründe zusammengestellt, warum sich Optimierung lohnt. Diese decken nicht alle möglichen projektspezifischen Vorteile ab, bieten jedoch eine allgemeine Perspektive.

Durchschnittliche Nutzer sind ungeduldig, und die Aufmerksamkeitsspanne wird jedes Jahr kürzer. Dank einer Studie, die 2015 von Microsoft veröffentlicht wurde, wissen wir, dass die durchschnittliche Aufmerksamkeitsspanne eines Menschen im Jahr 2000 noch 12 Sekunden betrug, während sie 2013 bereits auf 8 Sekunden gesunken war. Forscher haben diesen Wert mit der Aufmerksamkeitsspanne eines Goldfisches verglichen – und wir schneiden dabei nicht gut ab. Die Aufmerksamkeitsspanne dieses Wasserbewohners beträgt etwa 9 Sekunden.
Seit der Veröffentlichung dieser Studie sind fast 8 Jahre vergangen, sodass aktuelle Daten hilfreich wären. Dennoch deutet die zunehmende Popularität von Kurzformaten, wie sie in Apps wie dem berüchtigten TikTok verwendet werden, darauf hin, dass sich die Situation nicht verbessert.

Das stellt eine Herausforderung für alle dar, die erfolgreiche Software für ein breites Publikum entwickeln möchten – mit einer kurzen Aufmerksamkeitsspanne kommt auch Ungeduld. Eine App, die dem Benutzer keine angemessene und sofortige Rückmeldung gibt oder Operationen enthält, die unnötig lange dauern, kann schnell als „kaputt“ oder nicht benutzerfreundlich bewertet werden. Um den Erwartungen der Nutzer gerecht zu werden, sollte die Benutzeroberfläche unserer Anwendung reaktionsschnell sein und den Benutzern sofortiges Feedback bieten.
Die Laptops, die wir heute in unseren Rucksäcken tragen, oder die Smartphones in unseren Taschen sind exponentiell leistungsfähiger als ihre Gegenstücke von vor 10 Jahren. Mit dieser Rechenleistung können wir mehrere rechenintensive Anwendungen gleichzeitig ausführen.
Dennoch sind PCs und Mobilgeräte nicht die einzigen Plattformen, die wir täglich nutzen. Embedded-Geräte sind ein integraler Bestandteil zahlreicher Geräte und ermöglichen es Menschen, Touchscreens zu verwenden, verschiedene Aufgaben zu automatisieren oder Fernzugriffe zu nutzen. Für diese Plattform ist entscheidend, dass sie weitaus mehr Einschränkungen bei den Ressourcen hat als PCs oder Smartphones.
Um ein repräsentatives Smartphone für unsere mobile Plattform auszuwählen, habe ich mich für das Samsung S20FE entschieden. Es ist derzeit 3 Generationen alt, sodass wir vereinfachend sagen können, dass es ein durchschnittliches Telefon repräsentiert. Es verfügt über 6 GB RAM und einen 8-Kern-ARM-Prozessor mit 2,84 GHz. Für die Embedded-Plattform gibt es viele verschiedene Hardwarevarianten, die wir vergleichen könnten. Ein fairer Vergleichspunkt ist ein Single Board Computer oder ein Computer on Module, der sein eigenes vorinstalliertes Image für das Ausführen von Qt-Anwendungen mit Boot to Qt besitzt.
Nach einer weiteren Auswahl landen wir bei der Apalis iMX6 von Toradex. Die Low-End-Version startet mit 512 MB DDR3 RAM und einem 2-Kern-1-GHz-ARM-Prozessor. Die High-End-Version verfügt über eine Quad-Core-800-MHz-CPU und 2 GB RAM. Das ist bereits die höhere Leistungsklasse, da die Colibri iMX6ULL-Reihe bei nur 256 MB RAM und einer 1-Kern-528-MHz-CPU beginnt und bei 1 GB RAM und einer 1-Kern-800-MHz-CPU endet.

Man kann klar erkennen, dass der Unterschied in der verfügbaren Leistung erheblich ist. Das bringt wesentliche Unterschiede mit sich, wie wir für diese Plattformen entwickeln würden. In der Lage zu sein, den RAM-Verbrauch auf einer Embedded-Plattform um 40 MB zu reduzieren, wiegt deutlich schwerer, als dasselbe auf einem Smartphone zu tun.
Natürlich gibt es auch leistungsstärkere Optionen, aber um eine angemessene Perspektive zu erhalten, versetzen wir uns in ein hypothetisches Szenario. Wenn Sie einen erschwinglichen Smart-Toaster mit Qt entwickeln möchten, würden Sie lieber das Äquivalent einer RTX4090 einbauen oder etwas, das die Aufgabe erfüllt, ohne ein Vermögen zu kosten?
Durch die Optimierung von Software, um effizient auf Hardware mit niedrigeren Spezifikationen zu laufen, können Sie Software für eine breitere Zielgruppe zugänglich machen, die möglicherweise keinen Zugang zu High-End-Hardware hat. Das hilft Ihnen, mehr potenzielle Kunden zu erreichen und Ihr Produkt populärer zu machen.
Darüber hinaus kann die Verbesserung der Softwareleistung auch zu erheblichen Kosteneinsparungen führen. Wenn Sie Ihre Software zusammen mit der Hardware vertreiben, können Sie auf eine weniger leistungsstarke Plattform zurückgreifen, um diese auszuführen, wenn Sie einen ausreichenden Ressourcenpuffer schaffen. Dies ist besonders wichtig für die bereits erwähnten Embedded-Plattformen, aber es gilt auch für viele Systeme wie solche, die auf Thin-PC-Clients oder Tablets basieren.
Zusätzlich kann die Optimierung von Software langfristige Vorteile für eine Anwendung haben. Die Verbesserung der Effizienz und Geschwindigkeit kann auch den gesamten Ressourcenverbrauch der Software reduzieren. Durch die Minimierung der für den Betrieb von Backend-Diensten erforderlichen Ressourcen können Entwickler eine unnötige Skalierung der Infrastruktur vermeiden, was eine weitere Form der Kostensenkung darstellt.
Wenn neue Funktionen oder Komponenten zu einer Anwendung hinzugefügt werden, erfordern diese oft zusätzliche Ressourcen, wie CPU-Zyklen und Speicher, um zu laufen. Wenn die Anwendung bereits an ihrer maximalen Kapazität arbeitet, kann sie diese neuen Funktionalitäten möglicherweise nicht ohne Verlangsamung oder Abstürze aufnehmen. Durch die Optimierung der Software können Entwickler Ressourcen freisetzen und einen Leistungspuffer schaffen, der für die Einführung neuer Funktionselemente genutzt werden kann.
Da wir nun wissen, wie zusätzliche Anstrengungen zur Lösung von Optimierungsproblemen Ihrem Projekt zugutekommen können, konzentrieren wir uns darauf, wie wir die Optimierung der QML-App selbst durchführen können. In diesem Beitrag werde ich mich nur auf zwei allgemeine Techniken konzentrieren, aber weitere Inhalte zu diesem Thema werden in Kürze entwickelt und veröffentlicht.
Dieser Punkt mag für alle, die Qt verwenden, offensichtlich erscheinen. Da jedoch die Entwicklung einer Qt-QML-Anwendung auf einer mehrsprachigen Umgebung basiert, möchte ich noch einmal darauf eingehen, warum wir dies auf diese Weise tun. Meiner Meinung nach lassen sich die allgemeinen Vorteile der Verlageru der Geschäftslogik nach C++ in vier Kategorien zusammenfassen.

Der erste Vorteil, der bei der Verwendung von C++ erwähnt werden muss, ist natürlich die Leistung. C++ ist eine kompilierte Sprache, während QML interpretiert wird. Dies verschafft C++ einen Vorteil, da die Ausführung von Logik als Maschinencode deutlich schneller ist als die Ausführung von Code durch einen Interpreter. QML bietet zwar Tricks wie den Just-In-Time-Compiler, aber bei rechenintensiven Methoden zeigt sich der Unterschied deutlich.
C++ ist bekannt für sein ausgereiftes Ökosystem, das viele eingebaute Funktionalitäten sowie eine große Auswahl an Bibliotheken bietet. Warum sollte man das Rad neu erfinden, wenn man in den meisten Fällen vorhandene Algorithmen und APIs für grundlegende Funktionen wie Sortieren, Suchen, Filtern und vieles mehr nutzen kann? Viele großartige Entwickler haben bereits erhebliche Anstrengungen unternommen, um Optimierungsprobleme zu lösen. Warum nicht diese vorhandenen Lösungen nutzen und darauf aufbauen, um noch bessere Ergebnisse zu erzielen?
Die Compile-Time-Programmierung in C++ bezieht sich auf die Verwendung von Sprachmerkmalen, die es ermöglichen, Berechnungen und Operationen während des Kompilierungsprozesses durchzuführen. Diese Berechnungen und Operationen werden vom Compiler ausgewertet und in den ausführbaren Code integriert. Dadurch können einige Aufgaben, die normalerweise zur Laufzeit ausgeführt würden, stattdessen zur Kompilierungszeit erledigt werden, was die Leistung verbessern kann. Beispiele für Compile-Time-Programmiertechniken umfassen Template-Metaprogrammierung, die Verwendung des Schlüsselworts constexpr für die Compiler-Auswertung von Ausdrücken und Werten sowie vorab kompilierte Variablen wie QStringLiteral und QByteArrayLiteral.
Wenn wir unsere Logik nach C++ verlagern, können wir sie auch leicht durch die Einführung von Multithreading verbessern, sofern die Funktionalität dies zulässt. Parallele Programmierung ist nicht nur wichtig, weil die Nutzung ungenutzter CPU-Kerne es uns ermöglicht, mehrere aufgeteilte Operationen schneller auszuführen. Sie sorgt auch für eine gute Benutzererfahrung, indem rechenintensive Operationen vom Hauptthread entlastet werden. Der Hauptthread ist in der Regel für das Rendern der Benutzeroberfläche verantwortlich, und dessen Blockierung führt dazu, dass die Anwendung nicht mehr auf Benutzereingaben reagiert.
Beim Schreiben von Logik in C++ sollten wir darauf achten, dies effizient zu tun. Wenn wir ineffizienten Code schreiben und ihn mit einer gut optimierten JavaScript-Methode vergleichen, die direkt in einer QML-Datei platziert ist, könnten die Ergebnisse unbefriedigend ausfallen.
Lassen Sie uns nun ein schnelles Experiment durchführen und den C++- und JavaScript-Code zweier einfacher nichtlinearer Funktionen vergleichen, die die Quadratwurzel für Werte in einer Liste berechnen und eine Liste der Ergebnisse zurückgeben. Für JavaScript verwenden wir die sqrt-Funktion aus dem Math-Modul und für C++ die sqrt-Funktion aus der std-Bibliothek. Die Implementierung finden Sie im folgenden Beispiel:
C++ Code
CppLogicExample::CppLogicExample(QObject *parent)
: QObject{parent}
{
m_valuesCount = 1000000;
for(unsigned int i = 0; i < m_valuesCount; i++) {
m_values.append(QRandomGenerator::global()->generateDouble());
}
}
const QList<double> CppLogicExample::values() const
{
return m_values;
}
QList<double> CppLogicExample::calculateSqrt()
{
QList<double> output;
for(const double &val : m_values) {
output.append(sqrt(val));
}
return output;
}
QML Code
var values = cppLogicExample.values();
console.time("Sqrt - QML")
var jsOutput = []
for(let y = 0; y < values.length; y++) {
output.push(Math.sqrt(values[y]))
}
console.timeEnd("Sqrt - QML")
console.time("Sqrt - Cpp")
var cppOutput = cppLogicExample.calculateSqrt();
console.timeEnd("Sqrt - Cpp")
//Validation
console.assert(compareArrays(cppOutput, jsOutput), "Output differs!")
//...
function compareArrays(left, right) {
return left.length === right.length && left.every(function(value, index)
{ return value.toFixed(6) === right[index].toFixed(6)})
}
Schauen wir uns nun die Ergebnisse an:
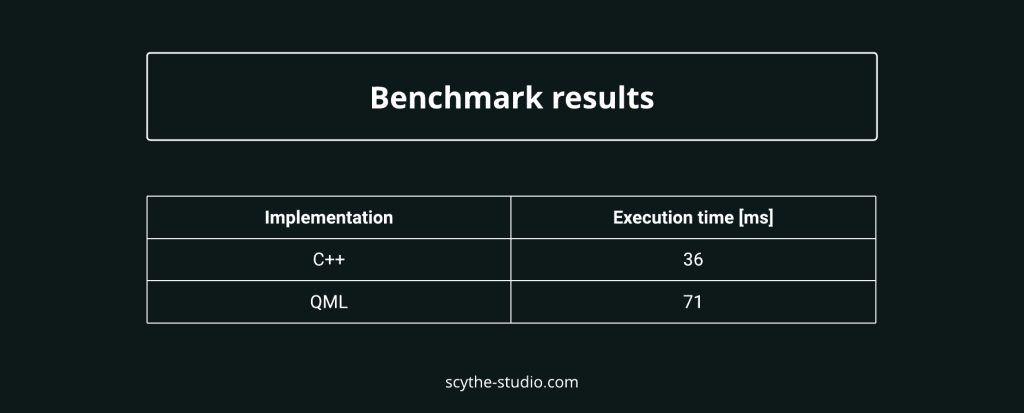
Obwohl dies ein grundlegender Vergleich ist, der hauptsächlich auf der Implementierung einer einzigen Methode basiert, können wir deutlich sehen, dass wir mit relativ wenig Aufwand die Ausführungszeit auf fast die Hälfte dessen reduzieren konnten, was wir in JavaScript hatten, indem wir in diesem speziellen Fall einfach C++ verwendet haben. Ein klarer Sieg für C++, aber was können wir als Nächstes damit machen?
Da wir bereits eine Schnittstelle zwischen C++ und QML erstellt haben, warum nicht unsere Optimierungsbemühungen auf die nächste Ebene heben und eine Design-Optimierung durchführen?
Der PC, auf dem ich die Benchmarks ausgeführt habe, verfügt über eine 8-Kern-/16-Thread-CPU, bei der die meisten Threads nichts getan haben, während der zuvor gezeigte Beispielcode ausgeführt wurde. Diese ungenutzten Ressourcen können wir nutzen, um die Leistung weiter zu verbessern. Um dies zu erreichen, können wir das Qt Concurrent-Modul und die map-Funktion verwenden, die eine Funktion für jedes Element einer gegebenen Sequenz ausführt.
C++ Code
QList<double> CppLogicExample::calculateSqrtAsynch()
{
QList<double> sequenceToModify = values();
QtConcurrent::blockingMap(sequenceToModify, [=](double& val){
val = sqrt(val);
});
return sequenceToModify;
}
QML Code
var values = cppLogicExample.values();
console.time("Sqrt - QML")
var jsOutput = []
for(let y = 0; y < values.length; y++) {
output.push(Math.sqrt(values[y]))
}
console.timeEnd("Sqrt - QML")
console.time("Sqrt - Cpp")
var cppOutput = cppLogicExample.calculateSqrt();
console.timeEnd("Sqrt - Cpp")
console.time("Sqrt - Cpp Asynch")
var asynchOutput = cppLogicExample.calculateSqrtAsynch();
console.timeEnd("Sqrt - Cpp Asynch")
//Validation
console.assert(compareArrays(cppOutput, jsOutput), "Output differs!")
console.assert(compareArrays(cppOutput, asynchOutput), "Output differs!")
Jetzt die wichtigste Frage: Was ist der Unterschied in der Ausführungszeit?

Mit nur drei Zeilen Codeänderung in unserer Methode konnten wir noch weiter gehen und die Ausführungszeit um weitere 70 % im Vergleich zur synchronen Ausführung und um 86 % im Vergleich zur Ausführung mit JavaScript-Methoden direkt in einer QML-Datei reduzieren.
Die Zahlen klingen beeindruckend, aber es mag nicht so spektakulär erscheinen, und einige Leser könnten denken, dass dies offensichtlich ist. Natürlich wird die Verarbeitung schneller, wenn wir viele Threads in der Anwendung verwenden. Was ich hervorheben wollte, ist, dass die Einführung von Multithreading in unserem Beispiel nur wenige Zeilen Code erforderte und dennoch eine signifikante Verbesserung brachte. Bei der Suche nach Optimierungsmöglichkeiten oder der Lösung eines Optimierungsproblems sollten wir immer versuchen, aus einer breiteren Perspektive zu schauen und nicht nur auf den logischen Ablauf der Funktionalität zu achten, sondern auch die verfügbaren Ressourcen in Betracht ziehen.
Qt-C++-Modelle sind ein grundlegendes Konzept im Qt-Framework, das eine Möglichkeit bietet, Daten in einer Anwendung zu repräsentieren und zu verwalten. Sie dienen dazu, die zugrunde liegenden Daten von der Benutzeroberfläche zu trennen und die Anzeige, Sortierung, Filterung und Bearbeitung von Daten auf verschiedene Weise zu erleichtern. Die C++-Modelle sind eng mit den in QML und Qt Quick verwendeten Ansichten integriert. Deshalb lassen sich die Vorteile in zwei Hauptkategorien einteilen.

Der erste Grund, Qt-C++-Modelle zu verwenden, ähnelt den bereits erwähnten Punkten. Mit Qt-C++-Modellen können Sie von bestehenden APIs, Schnittstellen und Signal-Handlern profitieren, um häufige Funktionen wie Filterung oder Sortierung zu implementieren, die in den Modellen integriert sind. Außerdem können Sie die STL-Bibliothek verwenden, um Ihre Logik zu schreiben.
Ein weiterer Grund für die Verwendung von Qt-Modellen ist die effiziente Verwaltung von Delegaten auf QML-Ebene, auf die ich etwas genauer eingehen möchte. Da die meisten Anwendungen dynamische Inhaltserstellung basierend auf den bereitgestellten Daten bieten, benötigen wir eine Möglichkeit, diese darzustellen. Das Anzeigen einer Fotogalerie, eines Chatverlaufs, von Berichten oder einer Dateisystemstruktur kann ressourcenintensiv sein, wenn wir einen großen Datensatz visualisieren müssen. Ich möchte zeigen, wie Qt-C++-Modelle es uns ermöglichen, dies effizient zu erreichen.
Zunächst erstellen wir ein einfaches Modell, indem wir ein Listenmodell mit Ganzzahlwerten verwenden. Zu Beginn füllen wir es mit 300 Werten und erstellen eine Eigenschaft, die den Zugriff darauf ermöglicht. Werfen Sie einen Blick auf das folgende Beispiel:
C++ Code
class ExampleModel : public QAbstractListModel
{
Q_OBJECT
Q_PROPERTY(QList<int> rawList READ rawList NOTIFY rawListChanged)
public:
explicit ExampleModel(QObject *parent = nullptr);
// QAbstractItemModel interface
virtual int rowCount(const QModelIndex &parent) const override;
virtual QVariant data(const QModelIndex &index, int role) const override;
virtual QHash<int, QByteArray> roleNames() const override;
const QList<int> &rawList() const;
Q_INVOKABLE void prependValueToModel();
signals:
void rawListChanged();
private:
QList<int> m_values;
};
namespace {
constexpr int m_targetSize {300};
}
ExampleModel::ExampleModel(QObject *parent)
: QAbstractListModel{parent}
{
m_values.fill(2137, m_targetSize);
}
int ExampleModel::rowCount(const QModelIndex &parent) const
{
return m_values.length();
}
QVariant ExampleModel::data(const QModelIndex &index, int role) const
{
if (!index.isValid()) {
return QVariant();
}
QVariant output;
if (role == Qt::DisplayRole) {
output = m_values.at(index.row());
}
return output;
}
QHash<int, QByteArray> ExampleModel::roleNames() const
{
QHash<int, QByteArray> roles;
roles.insert(Qt::DisplayRole, "text");
return roles;
}
const QList<int> &ExampleModel::rawList() const
{
return m_values;
}
void ExampleModel::prependValueToModel()
{
beginInsertRows(QModelIndex(), 0, 0);
m_values.prepend(444);
endInsertRows();
emit rawListChanged();
}
Nun ist es an der Zeit, die Daten zu visualisieren. Ich habe zwei nahezu identische ListViews erstellt – eine verwendet jedoch ein ListModel, während die andere eine einfache QList nutzt. Beide Modelle werden über Property Binding zugewiesen.
QML Code
ListView {
id: listViewWithoutModel
anchors {
top: parent.top
bottom: parent.bottom
left: parent.left
right: divider.left
}
model: ExampleModel.rawList
delegate: Text{
width: ListView.width
height: 30
verticalAlignment: Text.AlignVCenter
text: modelData
Component.onCompleted: {
console.count("****LIST: Delegate created")
}
Component.onDestruction: {
console.count("****LIST: Delegate destroyed")
}
}
}
ListView {
id: listViewWithModel
anchors {
top: parent.top
bottom: parent.bottom
left: divider.right
right: parent.right
}
model: ExampleModel
delegate: Text {
width: ListView.width
height: 30
verticalAlignment: Text.AlignVCenter
text: model.text
Component.onCompleted: {
console.count("####MODEL: Delegate created")
}
Component.onDestruction: {
console.count("####MODEL: Delegate destroyed")
}
}
}
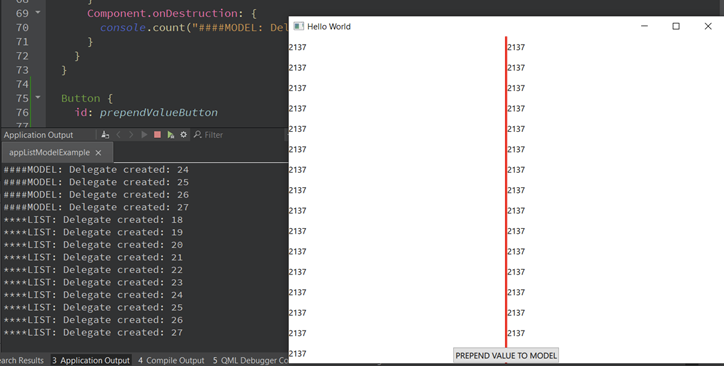
Wenn wir die App starten, scheint zunächst alles genau gleich zu funktionieren. Sowohl die modellbasierte als auch die listenbasierte Ansicht erstellen die gleiche Anzahl an Delegaten. Aber was passiert, wenn dem Modell ein neuer Wert hinzugefügt wird?
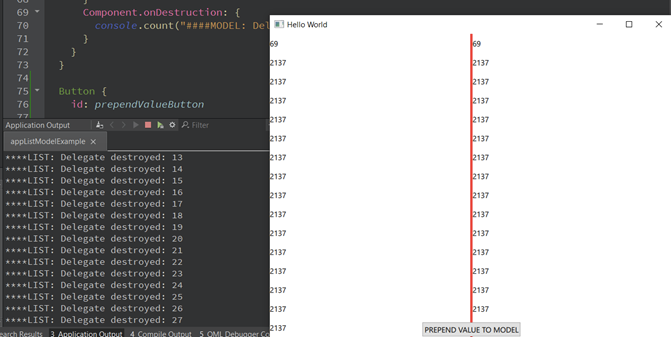
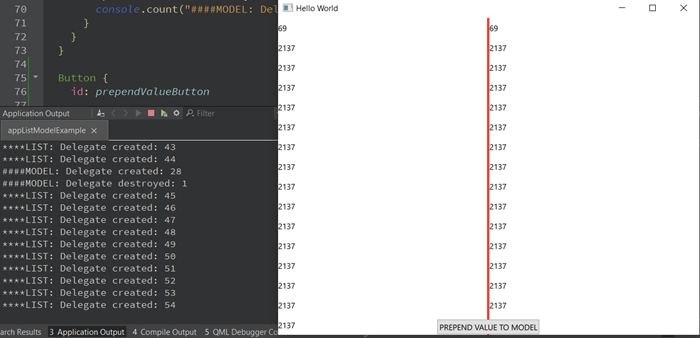
Man kann deutlich sehen, dass die auf QList basierende Ansicht in QML alle Delegaten zerstört hat. Warum passiert das? Das liegt daran, dass wir nur ein einziges Signal haben, um die Ansicht darüber zu informieren, dass sich etwas geändert hat. Die Ansicht hat keine genaue Kenntnis darüber, wo die Änderung stattgefunden hat. Daher bleibt ihr nichts anderes übrig, als alle Delegaten neu zu erstellen, um sicherzustellen, dass alle Delegaten aktuelle Werte haben. Die Neuerstellung aller Delegaten führt dazu, dass alle Eigenschaftsbindungen neu ausgewertet werden, was viele unnötige Operationen auslöst.
Das Modell hingegen hat nur einen einzigen Delegaten zerstört und einen neuen erstellt. Die Erstellung ist erwartungsgemäß, da wir gerade einen Wert eingefügt haben, aber die Zerstörung liegt einfach daran, dass der Delegat am unteren Rand aus dem Sichtfenster verschoben wurde. Die dynamische Erstellung von Delegaten kann die Leistung erheblich beeinflussen, insbesondere wenn komplexe Delegaten erstellt und Übergangs- oder Eigenschaftsanimationen verwendet werden, um die Benutzeroberfläche ansprechender zu gestalten.
Ich hoffe, dass Sie nach dem Lesen dieses Beitrags nicht nur eine klare Vorstellung davon haben, warum die Optimierung bestehender Funktionen in Software Ihre Zeit und Ressourcen wert ist, sondern auch etwas Neues über Techniken zur Optimierung von QML-basierten Anwendungen gelernt haben – anhand praktischer Beispiele.
Lassen Sie uns wissen, ob Ihnen der Beitrag gefallen hat. Wir freuen uns, ansprechende Inhalte für unsere Leser zu erstellen und in zukünftigen Beiträgen Themen rund um Optimierungen zu behandeln.
Wenn Sie Unterstützung bei der Entwicklung neuer Software oder der Verbesserung bestehender Software benötigen, schauen Sie sich die Dienstleistungen von Scythe Studio an. Wir sind ein Team von Enthusiasten, das sich auf die Entwicklung von Software mit Qt Quick & QML spezialisiert hat. Dank unserer Erfahrung und der Qualität unserer Lösungen tragen wir den Titel Qt Service Partner, was bestätigt, dass wir ein Softwarehaus sind, dem Sie vertrauen können.


Kommen wir zur Sache: Es ist eine Herausforderung, Top-Qt-QML-Entwickler zu finden. Helfen Sie sich selbst und starten Sie die Zusammenarbeit mit Scythe Studio – echten Experten im Qt C++ Framework.
Entdecken Sie unsere Fähigkeiten!Benutzer von eingebetteten Geräten – von Industriecontrollern bis hin zu Unterhaltungselektronik – sind sich oft nicht der versteckten Schwachstellen bewusst, […]

Grafische Benutzeroberflächen (GUIs) werden in eingebetteten Geräten – von Haushaltsgeräten bis hin zu medizinischer Ausrüstung – zunehmend wichtiger, um eine […]

Technische Manager im Embedded-Bereich stehen oft vor einer klassischen Herausforderung: die Integration industrieller Kommunikationsprotokolle in moderne Anwendungen. Eines der am […]
