
LVGL GUI Development: A Comprehensive Overview
Graphical user interfaces (GUIs) are becoming more and more important in embedded devices – from home appliances to medical equipment […]


Optimization is a crucial part of the software development process, which supports meeting many business goals, however, it requires resources that might be allocated somewhere else. Qt QML-based apps, like every piece of software, fall under this principle. In this post I want to talk about why optimizing your software is worth your effort as well as show some techniques you can use to improve the performance of apps leveraging Qt Quick.
In the beginning, I would like to clarify that when mentioning optimization I don’t have only the source level optimization in mind, but also refer to the design level optimization. Source-level optimization focuses on situations like wondering if `while(1)` is faster than `for(;;)`. The design level optimization base principle is just making sure that we make the best use of the available resources to reach our goals within the restrictions that we have.

Before we get to the nitty-gritty details of optimization techniques, let’s answer the most fundamental question. Why? For some of you, the answer to that question might be clear as day, but I still want to iterate on that and hope to spark a discussion.
In a perfect world, we should have an effective architecture which we would use to create optimal and efficient implementation right off the bat that will be used through the entire lifespan of the software. However, there is no human who can account for all of the possibilities during the project. Sudden expansion of scope with resource-consuming features, release of new standards and technologies which allow us to carry out the same logic in a more efficient way or simply a human error that caused the creation of non-optimal solutions are only a few things which might happen. There are many scenarios which might cause ending up with solutions which are not efficient enough but are still functional.
Why should we spend additional resources and time to modify already existing features which are integrated into the code base and are it worth it? To help you answer this question I’ve characterized 4 general reasons why optimization is worth your time. They are not covering all possible benefits which might be specific to your project but should give a general outlook.

Average users are impatient and the focus span is getting lower and lower every year. Thanks to the study published in 2015 by Microsoft, we know that in 2000 the average attention span of a human was 12 seconds, while in 2013 it was already only 8 seconds. Researchers have compared this value to an attention span of… a goldfish and we are not winning this comparison. The attention span of this water creature is around 9 seconds. It has already been almost 8 years since this study was published so we might need an update on the current data. However, short content formats getting a lot of popularity with apps like the infamous TikTok are hinting that the situation is not getting better.

This creates a challenge for anyone wanting to create successful software targeting a large audience – with a low attention span comes impatience. App which does not give proper and instant feedback to the user or has operations which take unnecessarily long can be rated as “broken” or not user-friendly. To match user expectations we should keep the UI of our application responsive as well as provide users with immediate feedback.
Nowadays, the laptops that we carry in our backpacks or phones in our pockets are exponentially more powerful than their counterparts from 10 years ago. With such power, we can run multiple heavy-computation applications at the same time. Nevertheless, PCs and mobile are not the only platforms which we use on a daily basis – there is one more which surrounds us. Embedded devices are an integral part of numerous appliances allowing people to control devices with touch screens, automate various tasks or use remote access. What is crucial for this platform is that is has much more resource constraints than PCs or smartphones.
By arbitrarily picking a smartphone that would represent our mobile platform I ended up with Samsung S20FE as a sample. It is currently 3 generations old so as a simplification we can say that it represents an average phone. It has 6Gb RAM and 8 core 2.84 GHz ARM processor. Now let’s pick comparison points for the embedded platform, but there are many different hardware positions which we might compare against. Going with the model of a Single Board Computer/Computer on Module which has its own pre-built image for running the Qt applications with Boot to Qt seems to be a fair pick.
After another arbitrary choice, we end up with Apalis iMX6 from Toradex. The low-end version starts with 512MB of DDR3 Ram and 2 core 1Ghz ARM processor, while the high-end version has a quad 800 Mhz CPU and 2Gb of RAM. This is already the higher tier line as Colibri iMX6ULL starts with just 256Mb or RAM and 1 core 528 Mhz CPU and ends with 1Gb 1 core 800 Mhz CPU.

We can clearly see that the difference in available power is significant. That carries a substantial difference to how we would develop on those platforms. Being able to minimize RAM footprint by 40MB on an embedded platform carries much more weight than doing the same thing on a smartphone.
Of course, there are other beefier options available but to get a proper point of view let’s put ourselves in a hypothetical scenario. If you would like to create an affordable smart toaster using Qt would you rather put an equivalent of RTX4090 in there or rather something which would do the trick but won’t cost an arm and a leg?
By optimizing software to run efficiently on hardware with lower specifications, you can make software accessible to a wider range of users who may not have access to high-end hardware. This helps you to reach more potential clients and make your product more popular.
Furthermore improving software performance can also lead to significant cost savings. If you distribute your software together with the hardware you can go with a less powerful platform to run it if you create a decent resource buffer. It is especially important for the before mentioned embedded platforms but is also applicable to many systems like ones that are based on thin PC clients or tablets.
Additionally, optimizing software can have long-term benefits for an application. Improving its efficiency and speed can also reduce the overall resource consumption of the software. By minimizing the amount of resources required for running backend services, developers can reduce unnecessary scaling of the infrastructure which is another form of cost improvement.
When new features or components are added to an application, they often require additional resources, such as CPU cycles and memory, to run. If the application is already operating at maximum capacity, it may not be able to accommodate these new functionalities without slowing down or crashing. By optimizing the software, developers can free up resources and create a performance buffer that can be used to introduce new functional elements.
As we now know how putting additional efforts into solving optimization problems can benefit your project, let’s focus on how we can perform optimization of the QML app itself. In this post, I will focus on only two general techniques, but more content on this topic is going to be developed and published soon.
This point might seem too obvious for everyone who is using Qt. However, as the development of a Qt QML application is based on a multi-language environment, I wanted to again iterate on why we are doing things this way. In my point of view, the general benefits of moving the business logic to C++ can be grouped into four categories.

The first benefit, which needs to be mentioned when bringing the C++ language, is of course performance. C++ is a compiled language while QML is an interpreted one. This gives C++ leverage as executing whole logic as machine code is much faster than running code through an interpreter. QML has some tricks up its sleeve like the Just-In-Time compiler but while running compute-heavy methods we can see the difference.
C++ is also known for being a mature ecosystem providing a lot of built-in functionalities as well as a rich selection of libraries. Why should you re-invent the wheel if in most basic cases you can use one of pre-existing algorithms and APIS for common functionalities like sorting, finding, filtering and doing much more? Many great developers have already put significant effort into solving optimization problems with those. Why not leverage those already existing solutions and keep on improving using them as a base for the solution?
Compile-time programming in C++ refers to the use of language features that enable computations and operations to be performed during the compilation process. These computations and operations are evaluated by the compiler and are used to generate the executable code. This means that some tasks that would otherwise be performed at runtime, can be performed at compile-time instead, which can improve performance. Example techniques of compile-time programming include template metaprogramming, marking expressions and values for compiler evaluation using constexpr keyword or usage of pre-compiled variables like QStringLiteral and QByteArrayLiteral.
When moving our logic to C++ we can also easily improve it by introducing multi-threading, if functionality allows that. Concurrent programming is important not only because using idle CPU cores allows us to perform multiple divided operations faster. It also ensures a good user experience by pulling demanding operations off the main thread. Usually, the main thread is responsible for rendering the user interface and blocking it causes the application to stop reacting to user input.
While writing logic in C++ we should also keep in mind to do that properly. If we write code which is not efficient and compare it against a well optimized JavaScript method, placed directly in a QML file, we might get unsatisfying results.
Now let’s do a quick experiment and compare C++ and JavaScript code of two simple nonlinear functions which calculate the square root for values in the list and return a list of results. For JavaScript I’m using `sqrt` function from `Math` module and `sqrt` from `std` library for C++. Implementation can be found in the following example:
C++ Code
CppLogicExample::CppLogicExample(QObject *parent)
: QObject{parent}
{
m_valuesCount = 1000000;
for(unsigned int i = 0; i < m_valuesCount; i++) {
m_values.append(QRandomGenerator::global()->generateDouble());
}
}
const QList<double> CppLogicExample::values() const
{
return m_values;
}
QList<double> CppLogicExample::calculateSqrt()
{
QList<double> output;
for(const double &val : m_values) {
output.append(sqrt(val));
}
return output;
}
QML Code
var values = cppLogicExample.values();
console.time("Sqrt - QML")
var jsOutput = []
for(let y = 0; y < values.length; y++) {
output.push(Math.sqrt(values[y]))
}
console.timeEnd("Sqrt - QML")
console.time("Sqrt - Cpp")
var cppOutput = cppLogicExample.calculateSqrt();
console.timeEnd("Sqrt - Cpp")
//Validation
console.assert(compareArrays(cppOutput, jsOutput), "Output differs!")
//...
function compareArrays(left, right) {
return left.length === right.length && left.every(function(value, index)
{ return value.toFixed(6) === right[index].toFixed(6)})
}
Now let’s take a look at the results:
| Benchmark results | |
|---|---|
| Implementation | Execution time [ms] |
| C++ | 36 |
| QML | 71 |
Although this is a basic comparison and is mostly based on comparing the implementation of one method we can clearly see that without much effort we could cut execution time to almost half of what we had in JavaScript by simply using C++ in that particular case. We have a clear win for C++, but what can we do with it next?
As we already created an interface between C++ and QML, why not go a level higher in our optimization efforts and do a design optimization?
PC that I’ve been running benchmarks on has an 8 core/16 thread CPU, where most of the threads were not doing anything while executing the example code shown before. We can use those idle resources to improve our performance further. To achieve that we can leverage the Qt Concurrent module and map function which will execute a function on every element of a given sequence.
C++ code
QList<double> CppLogicExample::calculateSqrtAsynch()
{
QList<double> sequenceToModify = values();
QtConcurrent::blockingMap(sequenceToModify, [=](double& val){
val = sqrt(val);
});
return sequenceToModify;
}
QML code
var values = cppLogicExample.values();
console.time("Sqrt - QML")
var jsOutput = []
for(let y = 0; y < values.length; y++) {
output.push(Math.sqrt(values[y]))
}
console.timeEnd("Sqrt - QML")
console.time("Sqrt - Cpp")
var cppOutput = cppLogicExample.calculateSqrt();
console.timeEnd("Sqrt - Cpp")
console.time("Sqrt - Cpp Asynch")
var asynchOutput = cppLogicExample.calculateSqrtAsynch();
console.timeEnd("Sqrt - Cpp Asynch")
//Validation
console.assert(compareArrays(cppOutput, jsOutput), "Output differs!")
console.assert(compareArrays(cppOutput, asynchOutput), "Output differs!")
Now the most important question. What is the difference in execution time?
| Benchmark results with concurrency | |
|---|---|
| Implementation | Execution time [ms] |
| Asynchronous C++ | 10 |
| Synchronous C++ | 36 |
| QML | 71 |
With a modification of just three lines of code in our method we were able to move even further and cut execution time by another 70% in comparison to synchronous execution and by 86% in comparison to executing it with JavaScript methods directly in a QML file.
The number sounds great but this might not look that impressive, and some of the readers might think that this is obvious. Of course, when we are using many threads in the app things will be done faster. What I wanted to point out is that the introduction of multi-threading in our example required adding only a few lines of code and gave a significant improvement. While looking for optimization possibilities or solving an optimization problem we should always try looking from a wider perspective and not only focus on the logical flow of the functionality but consider what resources are available.
Qt C++ Models are a fundamental concept in the Qt framework that provides a way to represent and manipulate data in an application. They are used to separate the underlying data from the user interface and to make it easier to display, sort, filter and manipulate data in various ways. The C++ models integrate tightly with the views used in the QML and Qt Quick. Because of that, we can group the benefits into two main categories.

The first reason for using Qt C++ models is similar to things already mentioned before. While using Qt C++ models you can benefit from pre-existing APIs, interfaces and signal handlers for implementing common features like filtering or sorting which are built into the models as well as use `stl` library while writing your logic.
Another reason for using Qt models is to provide efficient delegate management, on the QML level, which I wanted to focus on that a little bit more. As most of the applications provide some dynamic content creation based on the provided data we need a way to display it. Displaying a gallery of photos, chat history, reports or file system structure can be resource-consuming when we have a large dataset that needs to be visualized. I want to present how the Qt C++ models allow us to achieve that.
First of all, let’s create a simple model by going with list model containing integer values. In the beginning, we fill it with 300 values and create a property which will allow to retrieve it. Take a look at the following example:
C++ code
class ExampleModel : public QAbstractListModel
{
Q_OBJECT
Q_PROPERTY(QList<int> rawList READ rawList NOTIFY rawListChanged)
public:
explicit ExampleModel(QObject *parent = nullptr);
// QAbstractItemModel interface
virtual int rowCount(const QModelIndex &parent) const override;
virtual QVariant data(const QModelIndex &index, int role) const override;
virtual QHash<int, QByteArray> roleNames() const override;
const QList<int> &rawList() const;
Q_INVOKABLE void prependValueToModel();
signals:
void rawListChanged();
private:
QList<int> m_values;
};
namespace {
constexpr int m_targetSize {300};
}
ExampleModel::ExampleModel(QObject *parent)
: QAbstractListModel{parent}
{
m_values.fill(2137, m_targetSize);
}
int ExampleModel::rowCount(const QModelIndex &parent) const
{
return m_values.length();
}
QVariant ExampleModel::data(const QModelIndex &index, int role) const
{
if (!index.isValid()) {
return QVariant();
}
QVariant output;
if (role == Qt::DisplayRole) {
output = m_values.at(index.row());
}
return output;
}
QHash<int, QByteArray> ExampleModel::roleNames() const
{
QHash<int, QByteArray> roles;
roles.insert(Qt::DisplayRole, "text");
return roles;
}
const QList<int> &ExampleModel::rawList() const
{
return m_values;
}
void ExampleModel::prependValueToModel()
{
beginInsertRows(QModelIndex(), 0, 0);
m_values.prepend(444);
endInsertRows();
emit rawListChanged();
}
Now it is time to visualize the data. I’ve created almost exact same list views – one, however, is using a ListModel and the other uses a simple QList. Both of the models are assigned using property binding.
QML Code
ListView {
id: listViewWithoutModel
anchors {
top: parent.top
bottom: parent.bottom
left: parent.left
right: divider.left
}
model: ExampleModel.rawList
delegate: Text{
width: ListView.width
height: 30
verticalAlignment: Text.AlignVCenter
text: modelData
Component.onCompleted: {
console.count("****LIST: Delegate created")
}
Component.onDestruction: {
console.count("****LIST: Delegate destroyed")
}
}
}
ListView {
id: listViewWithModel
anchors {
top: parent.top
bottom: parent.bottom
left: divider.right
right: parent.right
}
model: ExampleModel
delegate: Text {
width: ListView.width
height: 30
verticalAlignment: Text.AlignVCenter
text: model.text
Component.onCompleted: {
console.count("####MODEL: Delegate created")
}
Component.onDestruction: {
console.count("####MODEL: Delegate destroyed")
}
}
}
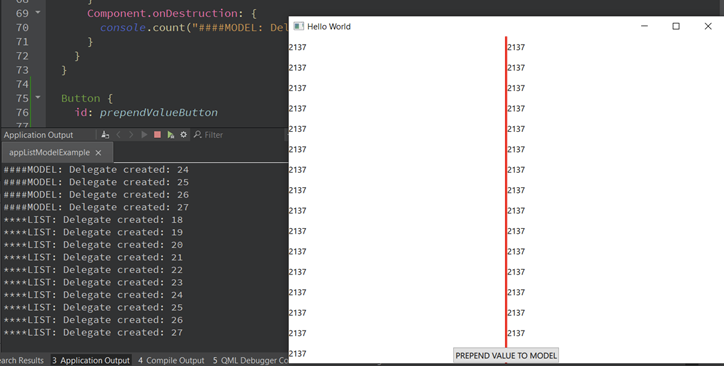
When we run the app at the beginning everything seems to work exactly the same. Both model-based and list-based views create the same amount of delegates. But what will happen when a new value is added to the model?
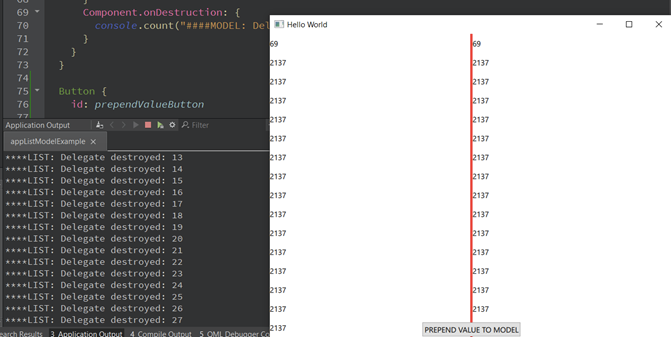
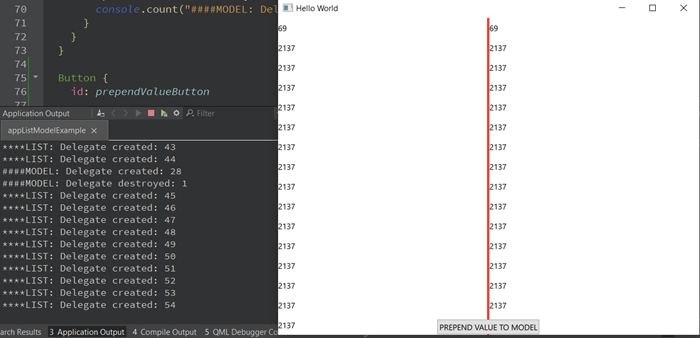
You can clearly see that the QList-based view in QML has destroyed all of the delegates. Why is that? It is because we only have a single signal for informing the view that something changed, and generally it has no idea where it happens so what it has to do is to recreate all of the delegates to make sure that all of the delegates have up-to-date values. The recreation of all of the delegates will cause all of the property bindings to be reevaluated which triggers a lot of unnecessary operations.
On the other hand, the model has destroyed a single delegate and created only one more. Creation is expected as we just inserted the value, but the destruction is simply caused by the fact that the delegate on the bottom went outside of the viewport. Dynamic creation of the delegates can heavily affect performance, especially if you create complex delegates and use transition or property animation to add more eye candy.
I hope that after reading this post you not only have a clear idea of why optimizing existing functionalities in software is worth your time and resources but also learned something new about techniques for the optimization of QML-based applications while taking a look at practical examples. Let us know if you liked the post as we will be happy to create engaging content for our readers and cover optimization-related topics in upcoming posts.
If you are looking for support in the development of new software or improving existing one check out Scythe Studio services. We are a group of enthusiasts, specializing in Qt Quick & QML software development. Thanks to our experience and the quality of provided solutions we hold the title of Qt Service Partner which is a confirmation that we are a software house you can trust.


Let's face it? It is a challenge to get top Qt QML developers on board. Help yourself and start the collaboration with Scythe Studio - real experts in Qt C++ framework.
Discover our capabilitiesGraphical user interfaces (GUIs) are becoming more and more important in embedded devices – from home appliances to medical equipment […]

Technical managers in the embedded space often face a classic challenge: integrating industrial communication protocols into modern applications. One such […]

Why is visualization so important in finance? First and foremost is clarity. Good visuals cut through complexity, making it easier […]
